About Me

UG @ IIEST Shibpur
deeponh.2004@gmail.com
Github
Google Scholar
I am from India 🇮🇳. I work as a Research Intern at AI4Bharat, IIT Madras under the guidance of Dr. Raj Dabre. I am also known as neuralnets. Feel free to contact me for any queries.
News
- 07.04.2026 : Scripts Through Time: A Survey of the Evolving Role of Transliteration in NLP has been accepted to ACL Findings 2026!
- 02.03.2026 : Not All Time is Gregorian has been accepted to ICBINB Workshop @ ICLR 2026!
- 22.02.2026 : Helped in reviewing one paper at ACL Jan ARR 2026
- 04.01.2026 : Riddlebench has been accepted at EACL Findings 2026!
- 05.11.2025 : CycleDistill has been accepted at WAT @ IJCNLP-AACL 2025!
- 30.10.2025 : Riddlebench Preprint is out!
- 07.08.2025 : CycleDistill has been accepted at MELT Workshop, CoLM!
- 13.07.2025 : Helped in reviewing two papers at MELT Workshop, CoLM
- 26.06.2025 : CycleDistill Preprint is out!
- 22.06.2025 : Helped in reviewing a paper at ACL May ARR 2025
- 30.05.2025 : I have passed my 2nd year with a CGPA of 8.91!
- 27.01.2025 : Joined AI4Bharat as a Research Intern!
Publications
2026
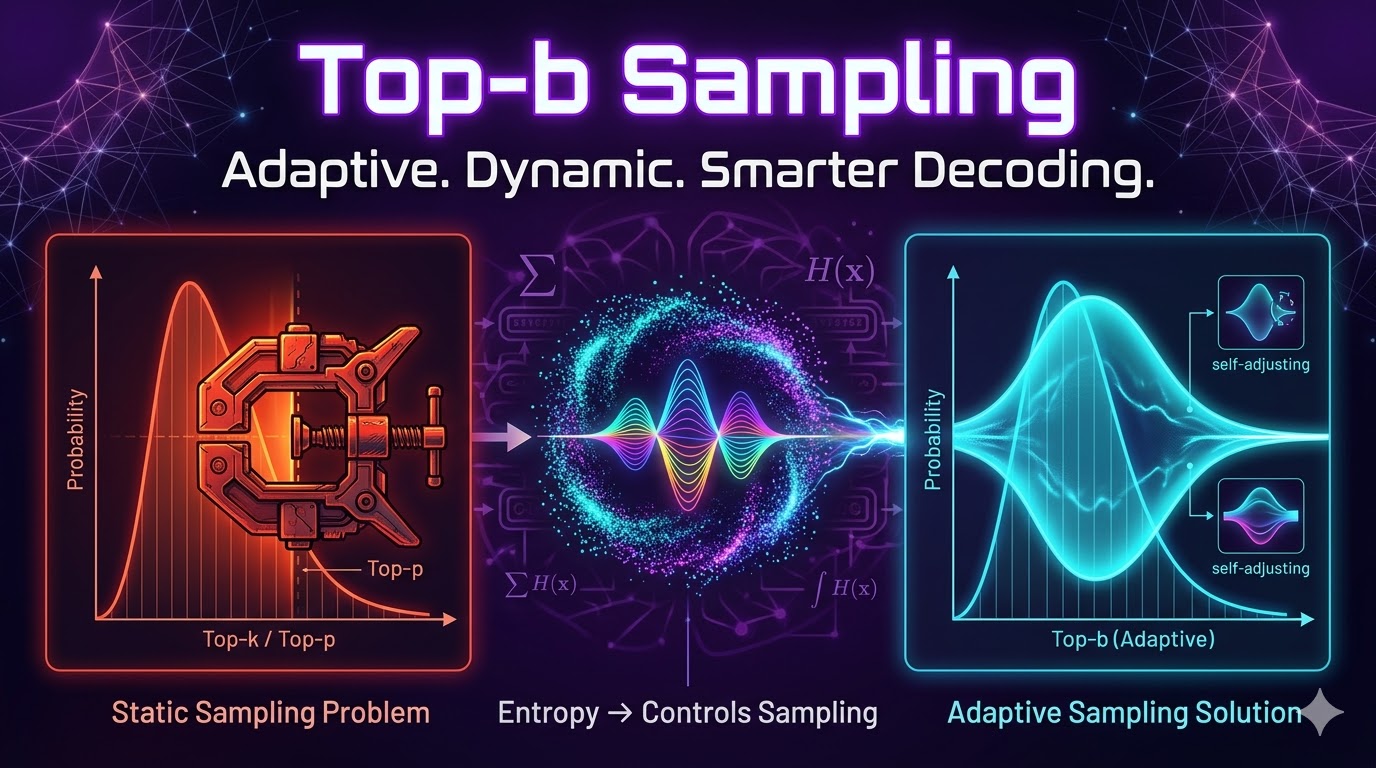 |
Top-b: Entropic Regulation of Relative Probability Bands in Autoregressive Language Processes Preprint |
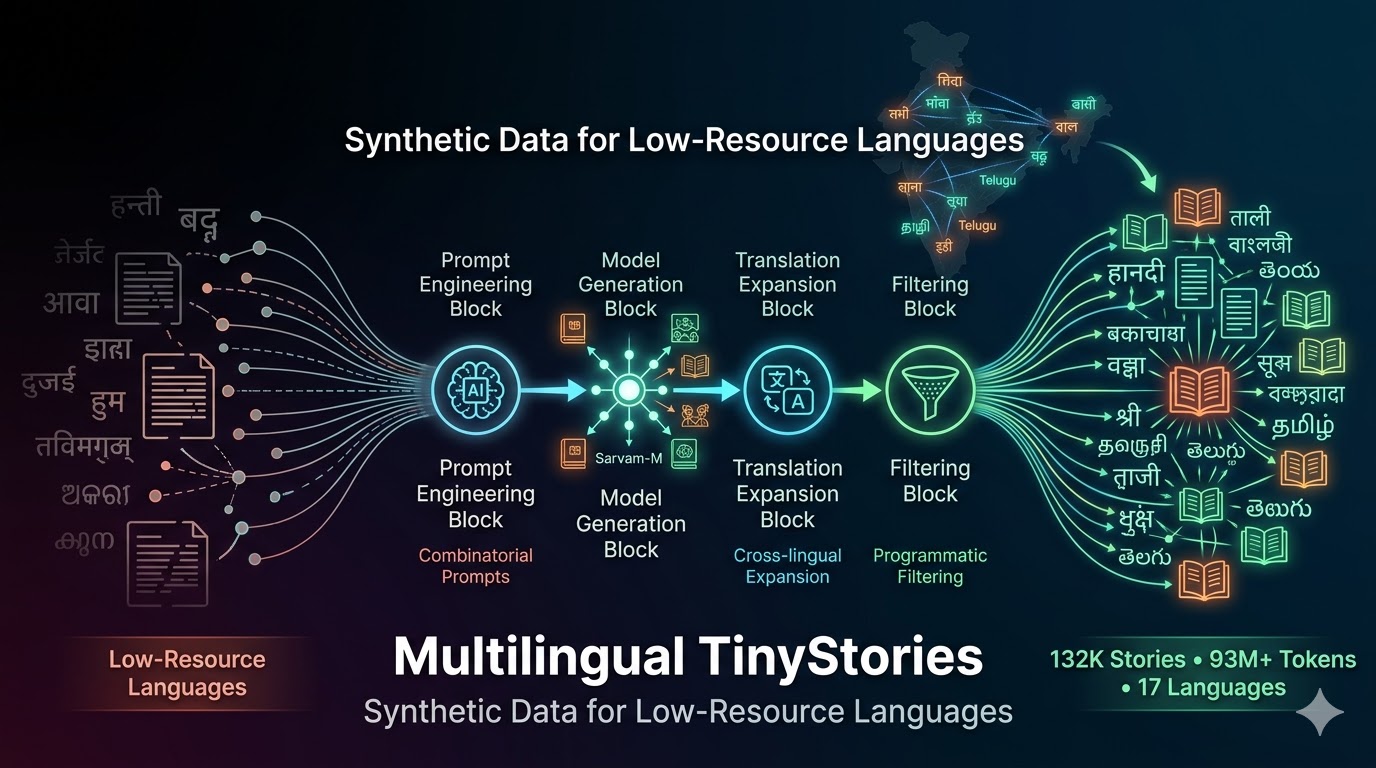 |
Multilingual TinyStories: A Synthetic Combinatorial Corpus of Indic Children's Stories for Training Small Language Models Preprint |
 |
Not All Time Is Gregorian: Evaluating LLMs on Cultural Calendar Systems ICBINB Workshop @ICLR 2026
|
 |
Scripts Through Time: A Survey of the Evolving Role of Transliteration in NLP ACL Findings 2026 |
2025
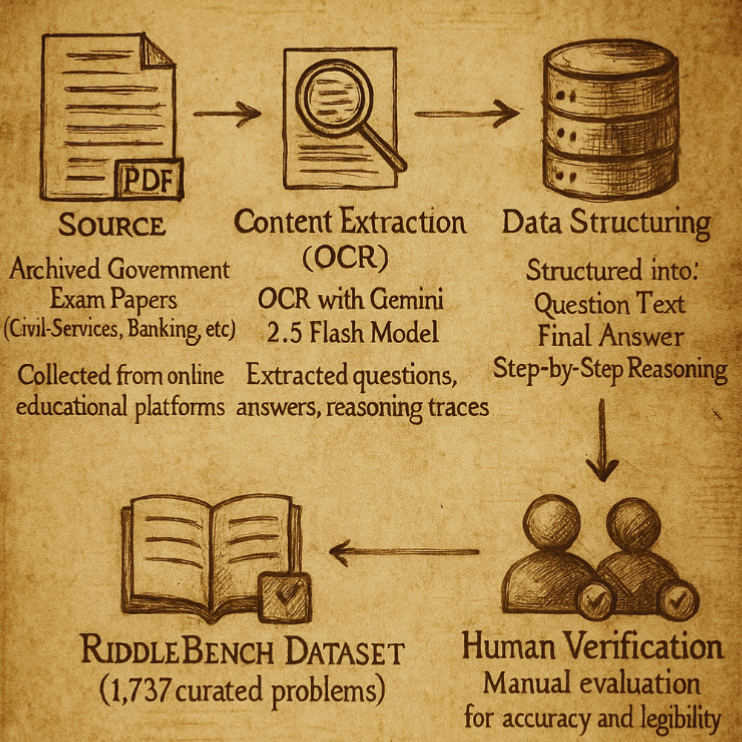 |
RiddleBench: A New Generative Reasoning Benchmark for LLMs EACL Findings 2026 |
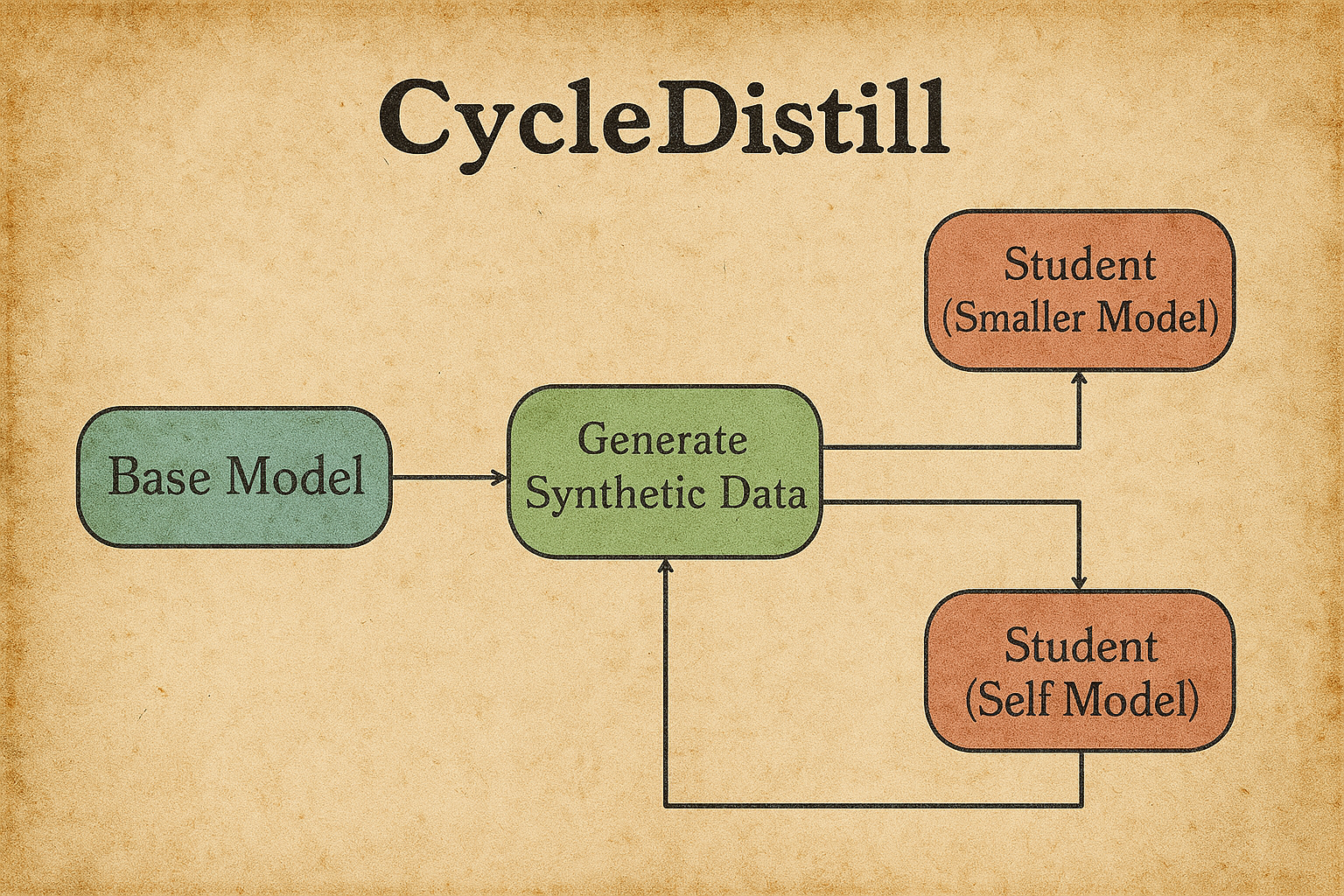 |
CycleDistill: Bootstrapping Machine Translation using LLMs with Cyclical Distillation MELT Workshop @ COLM 2025 / WAT @ IJCNLP-AACL 2025 |
 |
A Comprehensive Survey of Data Poisoning Attacks Survey Paper |
Projects
neugrad : Built a lightweight autograd engine in Python and NumPy, with tensor operations, automatic differentiation, backpropagation, and a scalable design for deep learning, mimicking PyTorch for education and experimentation.
Past Experience
Research Apprentice : IIEST Shibpur [July 2024 - Sept 2024]
Events and Achievements over Time
Winner - Braindead Hackathon : Won 1st prize at this hackathon by building a finetuned Mistral 7B to summarize texts
1st Runners Up - MCode Metallum : Coded up a modern to-do app and won 2nd prize
1st Runners Up - Startup Challenge @ IIEST: Made a project Auto@Kol, which aimed to connect the auto-rickshaw framework efficiently in Kolkata
2nd Runners Up - Hacknovare Instruo : Coded up a mental health management app and won the 3rd prize
Cohere ML School 2025 : Got selected - couldn't attend due to previous engagements
The Residency Feb 2025 : Got selected in the Bangalore Cohort of The Residency - didn't go
KVPY 2021 SA : Extra Merit List Scholar
JBNSTS Scholar : Selected in top 250 students in West Bengal
Technical Blogs
transformers: a deep dive into transformers and a visual guide into how it works.
optimizers: a deep dive into optimizers and a journey through time.
rnn: a deep dive into recurrent neural networks and how the math behind it works.
basics of nlp [part 1]: discussion into how text preprocessing, regex, frequencies, and word embeddings work.
basics of nlp [part 2]: discussion into how pos tagging, ner, sentiment analysis, and n-gram models work.
basics of nlp [part 3]: a guide into how hidden markov models, text clustering, attention work.
llms [part 1]: a guide into how embeddings, positional embeddings, tokenizer (especially bpe tokenizer) work.
enhance your model [part 1]: a guide into how lora, model distillation, gradient clipping and early stopping work.
llms [part 2]: a guide into how attention works, in great detail.
deepseek r1 explanation: a guide into how deepseek r1 works under the hood.
all about quantization: a guide into how quantization occurs in llms.
Talks & Podcasts
Talks or Podcasts I have done
- WAT 2025 Presentation of CycleDistill: Watch the session.
- Lossfunk Talk: Why LLMs Think in English and How It Affects Their Performance — link coming soon.
- Down the Research Rabbit Hole: From Curiosity to Contribution (RaSoR IIT Madras): Watch the session.
- Podcast with Siddhanth from IITBHU: Listen on YouTube.
- GDSC NIT Jalandhar Talk: Twitter Space recording.
If you can’t explain something to a first-year student, then you haven’t really understood it.
— R. Feynman